

So you’ve started to search about Data Architectures and heard a bunch of different (awkward) keywords… Traditional Data Lakes, Lambda and Kappa Processing Architectures. What does that even mean? 👀
Those are Data Architectures that we’re exploring in this article!! The idea is to explain in a simple way how they work , why they were created and give an example of each one! 😁
Before we start, check if you’re familiar with the following concepts (if not, start there):
Spoiler alert 🚨, it’s all an concept evolution!!
Traditional Data Lakes and Data Warehouses:
Imagine you’re an PM (product manager) and needs to be able to understand how users have been using the product you’ve been working into to present in a important meeting. To do so, every week you ask an engineer from your team to create a report about some metrics over the last year data alongside some other sources information.
Unfortunately over and over again the reports just take too long to be done, and often other stakeholders also have their own reports, but with different results from yours.
In this context Traditional Data Lakes and Warehouses were created. Using them as a central source of truth, companies can minimize the work/time to get reports in hands (get advanced analytics), democratize access to information (avoid non-matching reports about KPIs) and be able to use the power of Machine Learning.
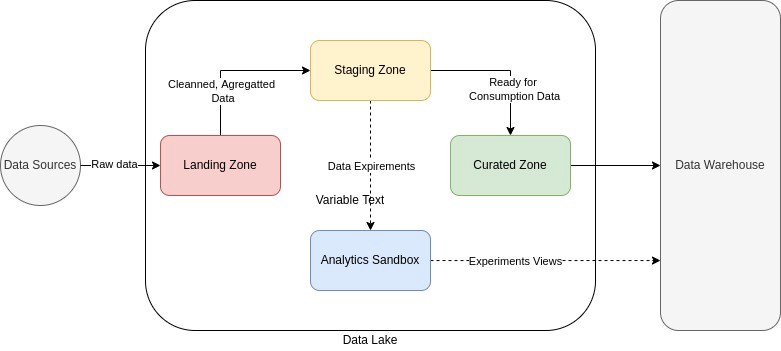
Traditional Data Lakes are usually a Blob Storage (S3, GCS, etc) or HDFS with batch loaded (from time to time) and a Batch Processing tool (usually Spark) that transforms data and send it to Data Lake zones.
Usually Data Lakes use the following name conventions for each zones (but in practice you may find many customized DLs):
- Landing Zone (AKA Raw Zone or Bronze Zone): All data loaded as is;
- Staging Zone (AKA Trusted Zone or Silver Zone): Mainly cleaned data, data delivered as agreements on data quality;
- Analytics Sandbox (AKA Refinement Zone, Silver Zone): Area where Data Engineers, Data Scientists and Data Analytics can discover, explore and experiment;
- Curated Data Zone (AKA Refined Zone, Gold Zone): All processed data, usually available for consuming by other applications and data professionals;
Data Warehouses are high volume analytical databases (BigQuery, RedShift, SnowFlake), with easily queryable data, Data Visualiztion tools are commonly seem connected to them. Usually inside DWs, data is formatted into dimensional schemas such as Star and Snowflake Schema.






{kind=link}